Regression and the age of the universe¶
Import scientific python packages¶
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
Bivariate data¶
There are many examples in Earth and Planetary Science where we are interested in the dependence of one set of data on another (bivariate data), such as the distance of the last geomagnetic reversal from the ridge crest to get spreading rate and the difference in arrival times of the $P$ and $S$ seismic waves, which is related to distance from the source to the receiver.
Today we will be focused on methods that allow us to investigate potential associations and relationships between variables. And using a classic problem from astrophysics to do so. The inspiration for this exercise came from Lecture 16 of Lisa Tauxe's Python for Earth Science Students class and some of the material is modified from those materials (https://github.com/ltauxe/Python-for-Earth-Science-Students).
Age of the universe¶
Today, we will focus on using the retreat velocity of galaxies and supernova as a function of their distance as our example data set. Such data underlies what has come to be known as "Hubble's Law" (same Hubble as for the Hubble telescope). Hubble published these results in 1929 [Hubble, E. P. (1929) Proc. Natl. Acad. Sci., 15, 168–173.]
At the time, it was unclear whether the universe was static, expanding, or collapsing. Hubble hypothesized that if the universe were expanding, then everything in it would be moving away from us. The greater the distance between the Earth and the galaxy, the faster it must be moving. So all that had to be done was to measure the distance and velocity of distant galaxies. Easy-peasy - right?
To measure velocity, Hubble made use of the doppler shift. To understand how this works, recall that the pitch you hear as an ambulance approaches changes. During doppler shift, the ambulance's pitch changes from high (as it approaches) to low (as it recedes). The pitch changes because the relative frequency of the sound waves changes. The frequency increases as the ambulance approaches, leading to a higher pitch, and then decreases as it moves away, resulting in a lower pitch.
Just in case you haven't had this life experience, let's listen to such a siren here: https://www.youtube.com/watch?v=imoxDcn2Sgo

The same principle applies to light, but rather than hear a change in frequency, we observe a shift in the wavelength (the color) emitted by the galaxy. If a star or galaxy is moving away from us, its absorption bands are shifted towards longer wavelengths - the red end of the visible spectrum. The faster the star or galaxy travels away from the observer, the greater the shift will be to the red:
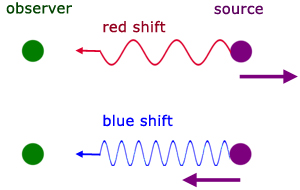
So a star (or galaxy) moving away from us will have a red shift with the wavelength being spread out.
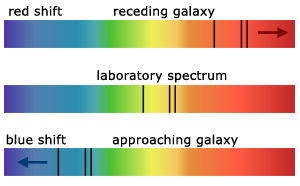
Figures from http://www.a-levelphysicstutor.com/wav-doppler.php
Hubble measured the red shift of different galaxies and converted them to velocities. He then estimated the distance to these objects, which is harder to do (and he was pretty far off).
Improving such data was a major motivation of the Hubble Space Telescope. Those data and continued improvement to approaches for estimating these distances and velocities and investigating additional types of celestial objects is a major focus of ongoing research.
Type 1a supernovae data¶
Let's import data from Freedman et al. (2000) of the distance and retreat velocity of type 1a supernovae. These supernovae are described as follows in a review paper that Freedman wrote in 2010 (https://doi.org/10.1146/annurev-astro-082708-101829):
One of the most accurate means of measuring cosmological distances out into the Hubble flow utilizes the peak brightness of SNe Ia. The potential of supernovae for measuring distances was clear to early researchers (e.g., Baade, Minkowski, Zwicky), but it was the Hubble diagram of Kowal (1968) that set the modern course for this field, followed by decades of work by Sandage, Tammann, and collaborators (e.g., Sandage & Tammann 1982, 1990; see also the review by Branch 1998). Analysis by Pskovskii (1984), followed by Phillips (1993), established a correlation between the magnitude of a SN Ia at peak brightness and the rate at which it declines, thus allowing supernova luminosities to be “standardized.” This method currently probes farthest into the unperturbed Hubble flow, and it possesses very low intrinsic scatter: Freedman and Madore (2010) who then go onto describe how using Cepheid variable stars (a type of pulsating star) has allowed for the distances to be better calibrated.
SNe Ia result from the thermonuclear runaway explosions of stars. From observations alone, the presence of SNe Ia in elliptical galaxies suggests that they do not come from massive stars. Many details of the explosion are not yet well understood, but the generally accepted view is that of a carbon-oxygen, electron-degenerate, nearly-Chandrasekharmass white dwarf orbiting in a binary system with a close companion Freedman and Madore (2010)
Supernova_data = pd.read_csv('data/Freedman2000_Supernova1a.csv')
Supernova_data.tail()
| Supernova | VCMB | D(Mpc) | HCMB | σ | |
|---|---|---|---|---|---|
| 31 | SN1994T | 10715 | 149.9 | 71.5 | 2.6 |
| 32 | SN1995ac | 14634 | 185.6 | 78.8 | 2.7 |
| 33 | SN1995ak | 6673 | 82.4 | 80.9 | 2.8 |
| 34 | SN1996C | 9024 | 136.0 | 66.3 | 2.5 |
| 35 | SN1996bl | 10446 | 132.7 | 78.7 | 2.7 |
The VCMB column is velocity relative to the cosmic microwave background in $km \cdot s^{-1}$ .
The D(Mpc) column is the distance in Mpc which is the unit typically used for these measurements. 1 Mpc = 3.09 x $10^{19}$ km
Go ahead and double-click on this cell to see how I am getting labels that have the proper superscripts.
To create nice labels with superscripts, we can use latex formatting, which can also be done in a markdown cell. For a superscript, first we need to encase the text in dollar signs and then use the ^ symbol to make the following text a superscript. If there is more than one number in the superscript, you must enclose what you want as the superscript in curly braces. For example, to print $10^3$, we use $10^3$ and for 'per second' ($s^{-1}$)
plt.figure()
plt.scatter(Supernova_data['D(Mpc)'],Supernova_data['VCMB'],color='red',label='1A Supernovae data (Freedman et al. 2000)')
plt.ylabel('Velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.legend()
plt.show()

Determining the slope of this line (the Hubble constant)¶
We have distance on the x-axis in megaparsecs and velocity on the y-axis in km/s. The slope of this line is the Hubble constant:
$v = H_o d$
where $v$ is velocity, $d$ is distance, and $H_o$ is the Hubble constant.
This looks a lot like the equation for a line through the data ($y=Ax + b$) where $A$ is the slope and $b$ is the y-intercept. In this case, the y-intercept should be 0 or nearly so, and $m$ is $H_o$.
So how do we find the slope?
Here is where we can use linear regression to find the "best fit" line through the data. The approach is to minimize the sum of the squares of the distances (residuals) between the points and a line through them. In this illustration below, the residuals are the vertical distance between each data point and the line:
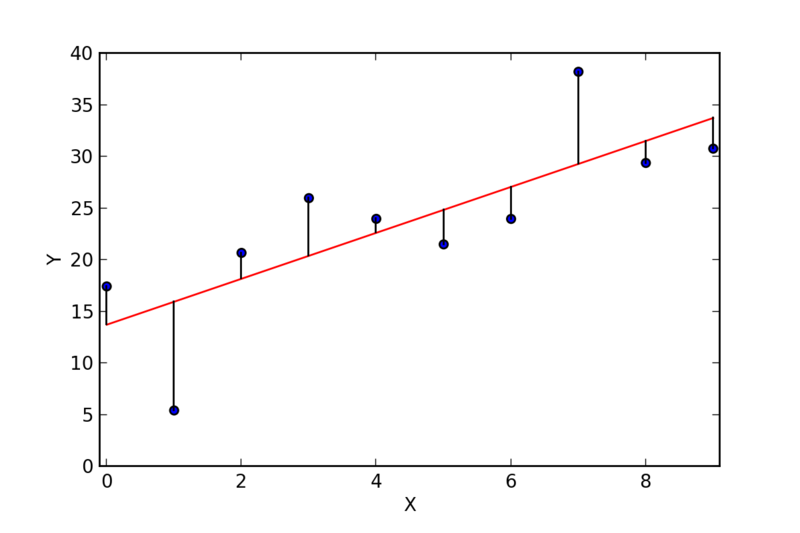
The approach in linear regression is to find the line that minimizes the squared value of these distances all added up.
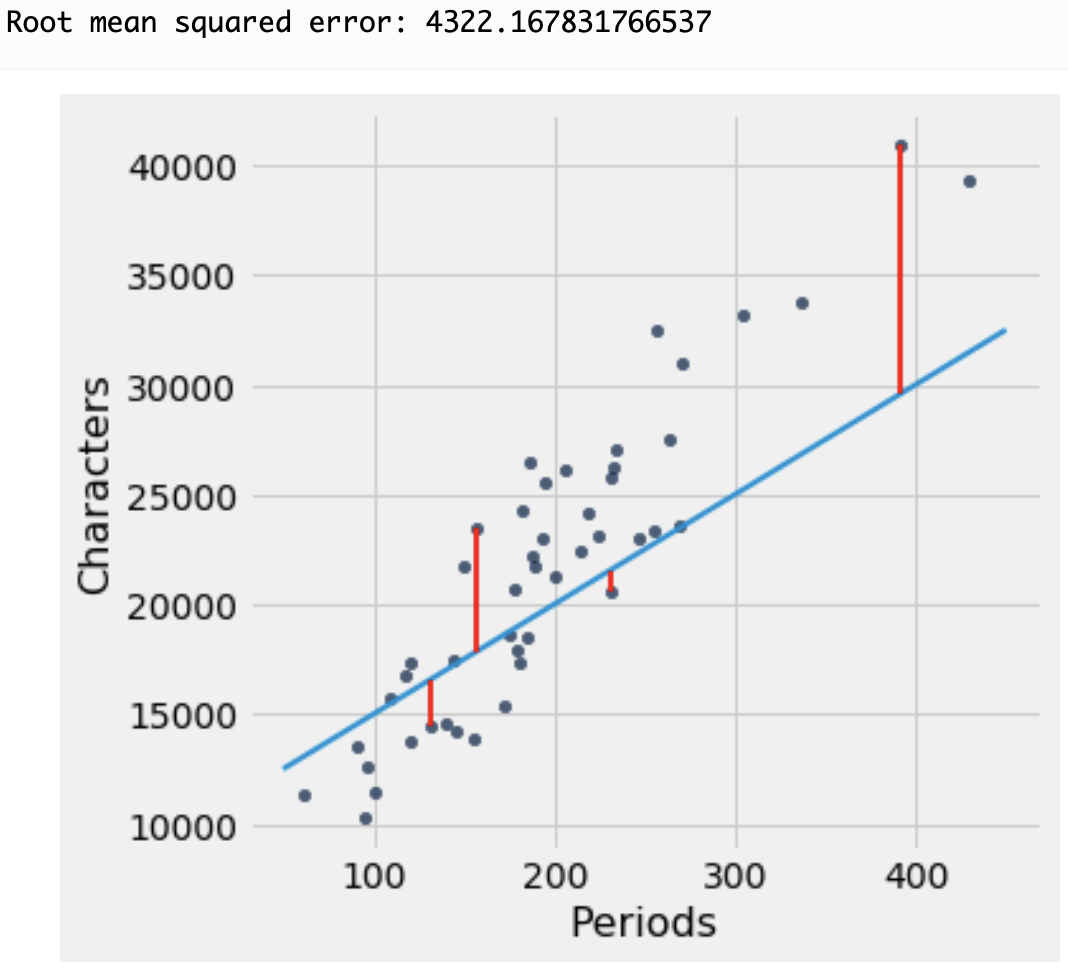
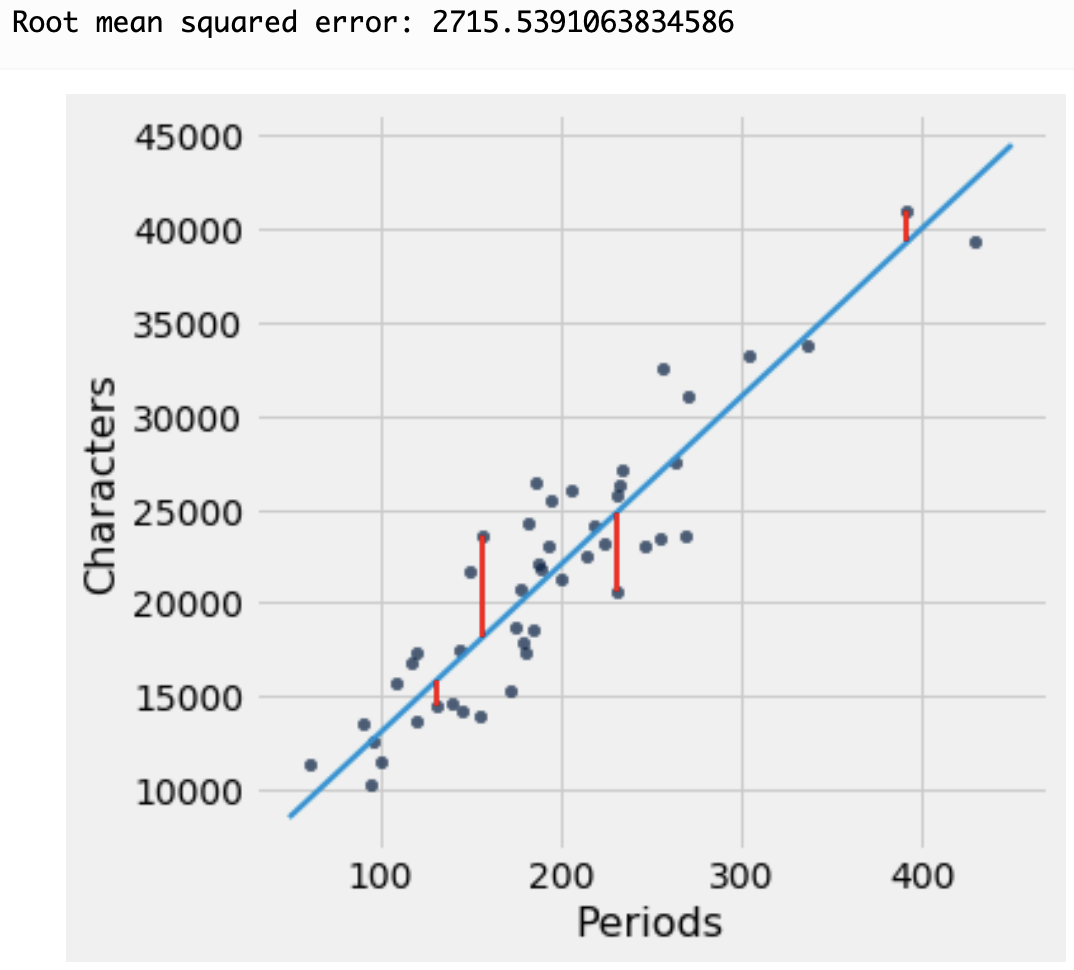
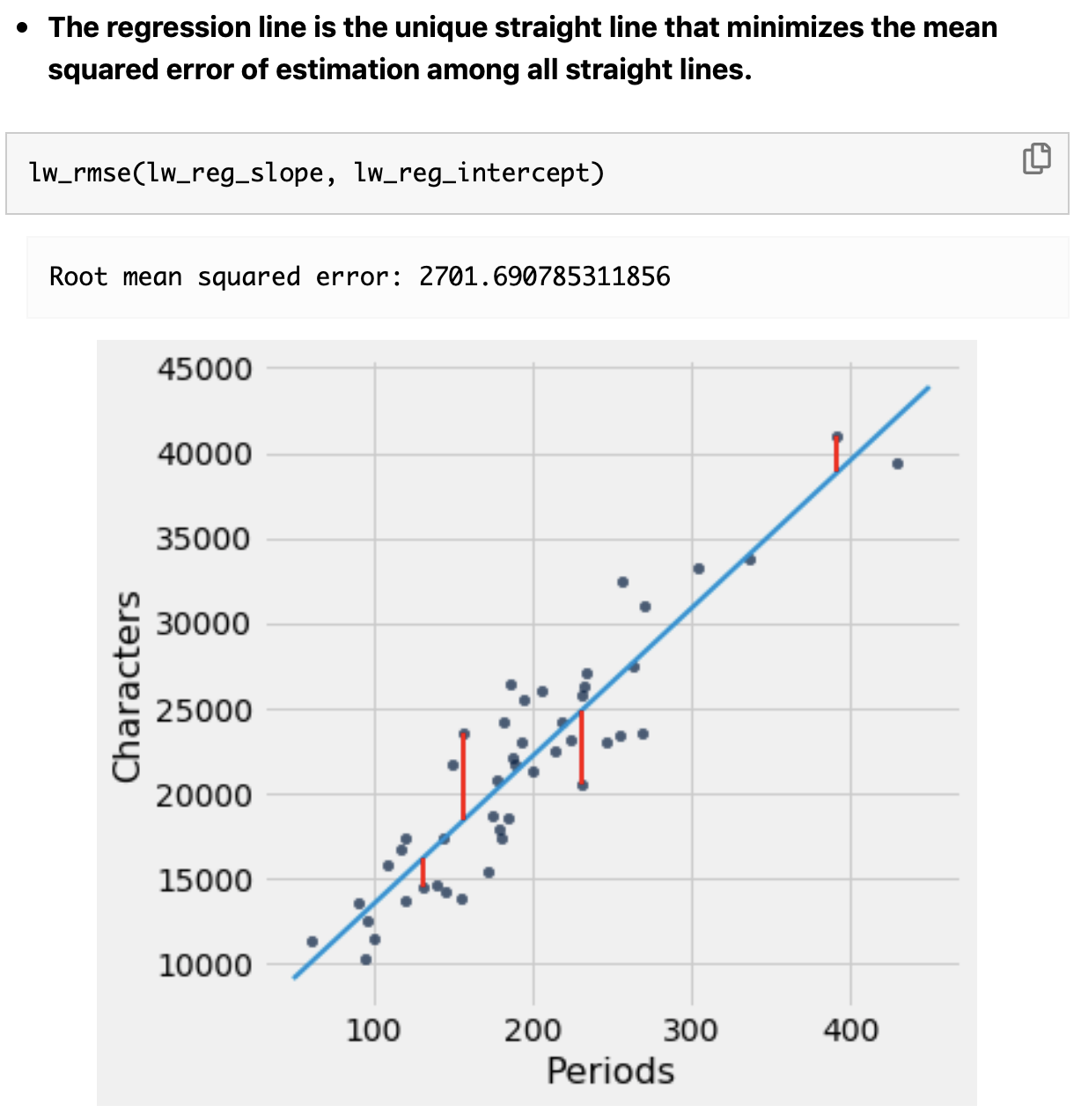
We determine the best-fit line through this least squares approach using scikit-learn.
LinearRegression?
Init signature: LinearRegression( *, fit_intercept=True, copy_X=True, n_jobs=None, positive=False, ) Docstring: Ordinary least squares Linear Regression. LinearRegression fits a linear model with coefficients w = (w1, ..., wp) to minimize the residual sum of squares between the observed targets in the dataset, and the targets predicted by the linear approximation. Parameters ---------- fit_intercept : bool, default=True Whether to calculate the intercept for this model. If set to False, no intercept will be used in calculations (i.e. data is expected to be centered). copy_X : bool, default=True If True, X will be copied; else, it may be overwritten. n_jobs : int, default=None The number of jobs to use for the computation. This will only provide speedup in case of sufficiently large problems, that is if firstly `n_targets > 1` and secondly `X` is sparse or if `positive` is set to `True`. ``None`` means 1 unless in a :obj:`joblib.parallel_backend` context. ``-1`` means using all processors. See :term:`Glossary <n_jobs>` for more details. positive : bool, default=False When set to ``True``, forces the coefficients to be positive. This option is only supported for dense arrays. .. versionadded:: 0.24 Attributes ---------- coef_ : array of shape (n_features, ) or (n_targets, n_features) Estimated coefficients for the linear regression problem. If multiple targets are passed during the fit (y 2D), this is a 2D array of shape (n_targets, n_features), while if only one target is passed, this is a 1D array of length n_features. rank_ : int Rank of matrix `X`. Only available when `X` is dense. singular_ : array of shape (min(X, y),) Singular values of `X`. Only available when `X` is dense. intercept_ : float or array of shape (n_targets,) Independent term in the linear model. Set to 0.0 if `fit_intercept = False`. n_features_in_ : int Number of features seen during :term:`fit`. .. versionadded:: 0.24 feature_names_in_ : ndarray of shape (`n_features_in_`,) Names of features seen during :term:`fit`. Defined only when `X` has feature names that are all strings. .. versionadded:: 1.0 See Also -------- Ridge : Ridge regression addresses some of the problems of Ordinary Least Squares by imposing a penalty on the size of the coefficients with l2 regularization. Lasso : The Lasso is a linear model that estimates sparse coefficients with l1 regularization. ElasticNet : Elastic-Net is a linear regression model trained with both l1 and l2 -norm regularization of the coefficients. Notes ----- From the implementation point of view, this is just plain Ordinary Least Squares (scipy.linalg.lstsq) or Non Negative Least Squares (scipy.optimize.nnls) wrapped as a predictor object. Examples -------- >>> import numpy as np >>> from sklearn.linear_model import LinearRegression >>> X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]]) >>> # y = 1 * x_0 + 2 * x_1 + 3 >>> y = np.dot(X, np.array([1, 2])) + 3 >>> reg = LinearRegression().fit(X, y) >>> reg.score(X, y) 1.0 >>> reg.coef_ array([1., 2.]) >>> reg.intercept_ 3.0... >>> reg.predict(np.array([[3, 5]])) array([16.]) File: ~/.local/miniconda3/lib/python3.10/site-packages/sklearn/linear_model/_base.py Type: ABCMeta Subclasses:
PolynomialFeatures?
Init signature: PolynomialFeatures( degree=2, *, interaction_only=False, include_bias=True, order='C', ) Docstring: Generate polynomial and interaction features. Generate a new feature matrix consisting of all polynomial combinations of the features with degree less than or equal to the specified degree. For example, if an input sample is two dimensional and of the form [a, b], the degree-2 polynomial features are [1, a, b, a^2, ab, b^2]. Read more in the :ref:`User Guide <polynomial_features>`. Parameters ---------- degree : int or tuple (min_degree, max_degree), default=2 If a single int is given, it specifies the maximal degree of the polynomial features. If a tuple `(min_degree, max_degree)` is passed, then `min_degree` is the minimum and `max_degree` is the maximum polynomial degree of the generated features. Note that `min_degree=0` and `min_degree=1` are equivalent as outputting the degree zero term is determined by `include_bias`. interaction_only : bool, default=False If `True`, only interaction features are produced: features that are products of at most `degree` *distinct* input features, i.e. terms with power of 2 or higher of the same input feature are excluded: - included: `x[0]`, `x[1]`, `x[0] * x[1]`, etc. - excluded: `x[0] ** 2`, `x[0] ** 2 * x[1]`, etc. include_bias : bool, default=True If `True` (default), then include a bias column, the feature in which all polynomial powers are zero (i.e. a column of ones - acts as an intercept term in a linear model). order : {'C', 'F'}, default='C' Order of output array in the dense case. `'F'` order is faster to compute, but may slow down subsequent estimators. .. versionadded:: 0.21 Attributes ---------- powers_ : ndarray of shape (`n_output_features_`, `n_features_in_`) `powers_[i, j]` is the exponent of the jth input in the ith output. n_features_in_ : int Number of features seen during :term:`fit`. .. versionadded:: 0.24 feature_names_in_ : ndarray of shape (`n_features_in_`,) Names of features seen during :term:`fit`. Defined only when `X` has feature names that are all strings. .. versionadded:: 1.0 n_output_features_ : int The total number of polynomial output features. The number of output features is computed by iterating over all suitably sized combinations of input features. See Also -------- SplineTransformer : Transformer that generates univariate B-spline bases for features. Notes ----- Be aware that the number of features in the output array scales polynomially in the number of features of the input array, and exponentially in the degree. High degrees can cause overfitting. See :ref:`examples/linear_model/plot_polynomial_interpolation.py <sphx_glr_auto_examples_linear_model_plot_polynomial_interpolation.py>` Examples -------- >>> import numpy as np >>> from sklearn.preprocessing import PolynomialFeatures >>> X = np.arange(6).reshape(3, 2) >>> X array([[0, 1], [2, 3], [4, 5]]) >>> poly = PolynomialFeatures(2) >>> poly.fit_transform(X) array([[ 1., 0., 1., 0., 0., 1.], [ 1., 2., 3., 4., 6., 9.], [ 1., 4., 5., 16., 20., 25.]]) >>> poly = PolynomialFeatures(interaction_only=True) >>> poly.fit_transform(X) array([[ 1., 0., 1., 0.], [ 1., 2., 3., 6.], [ 1., 4., 5., 20.]]) File: ~/.local/miniconda3/lib/python3.10/site-packages/sklearn/preprocessing/_polynomial.py Type: type Subclasses:
Fitting a line with scikit-learn¶
X = Supernova_data[['D(Mpc)']].values
y = Supernova_data['VCMB'].values
model = LinearRegression()
model.fit(X,y)
print('Slope:',model.coef_)
print('Intercept:',model.intercept_)
Slope: [67.5361857] Intercept: 711.795667873037
So $H_o$, the slope of the best-fit line, is 67.5 (in the odd units of kilometers per second per megaparsec).
Let's plot the best fit line on our graph.
y_pred = model.predict(X)
plt.figure()
plt.scatter(Supernova_data['D(Mpc)'],Supernova_data['VCMB'],color='red',label='1A Supernovae data (Freedman et al. 2000)')
plt.plot(Supernova_data['D(Mpc)'],y_pred,color='blue',label='Linear fit')
plt.ylabel('Velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.legend()
plt.show()

Using this linear model for prediction¶
What would we predict that the velocity would be for a supernova that happened to be 350 Mpc?
y_350 = model.predict([[350]])
print('Predicted velocity at 350 Mpc:',y_350)
Predicted velocity at 350 Mpc: [24349.46066402]
Evaluating model fit¶
We'd also like to know who well this model fits our data (i.e. how correlated the data are). We'll use the $R^{2}$ correlation coefficient for this. $R^{2}$ is zero for uncorrelated data, and 1 for perfectly linear data (so no misfit between the model line and data).
Review how to calculate $R^{2}$:
$R^{2} = 1 - \frac{SS_{res}}{SS_{tot}}$
where $SS_{res}$ is the sum of the squares of the residuals $SS_{res} = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2$,
and $SS_{tot}$ is the total sum of the squares of the data $SS_{tot} = \sum_{i=1}^{n} (y_i - \bar{y})^2$.
And use it, to get what is normally called the $R^2$ value, which when 1. represents perfect agreement.

Pearson correlation coefficient between several example X,Y sets. Source: https://en.wikipedia.org/wiki/Correlation_and_dependence
ss_res = np.sum((y - y_pred)**2)
ss_tot = np.sum((y - np.mean(y))**2)
r2 = 1 - (ss_res / ss_tot)
print('R^2:',r2)
R^2: 0.9782780292778982
Not a bad fit! We can have confidence that there is a strong correlation between distance and velocity. The universe is expanding.
Evaluting the fit through plotting residuals¶
To see how well the regression performs, the data scientist must measure how far off the estimates are from the actual values. These differences are called residuals.
$$ \epsilon_i = y_i - \hat{y}_i $$
where $\epsilon_i$ is the residual for the $i$th data point, $y_i$ is the observed value, and $\hat{y}_i$ is the regression estimate.
A residual is what's left over – the residue – after estimation.
Residuals are the vertical distances of the points from the regression line. There is one residual for each point in the scatter plot. The residual is the difference between the observed value of $y$ and the fitted value of $y$, so for the point $(x, y)$,
res = y - y_pred
plt.figure()
plt.scatter(Supernova_data['D(Mpc)'], res, color='red', label='Residuals')
plt.hlines(0,xmin=0,xmax=500)
plt.xlim(0,500)
plt.show()

The residual plot of a good regression shows no pattern. The residuals look about the same, above and below the horizontal line at 0, across the range of the predictor variable.
Estimating the age of the universe¶
To calculate the age of the universe, we can use Hubble's law:
We had $v=H_o d$ as Hubble's law and we know that distance = velocity x time, or, $d=vt$. So, if we divide both sides by $v$ and we get:
$1 = H_o t$.
Solving for $t$ (the age of the universe), we get
$t=1/H_o$ [in some weird units.]
H0 = model.coef_[0]
t = 1.0/H0
print(t)
0.014806877077622455
But the units are weird (not years, Mpc s/km). To fix this, we need to know how many kilometers are in a megaparsec. As it happens, there are 3.09 x $10^{19}$ km/Mpc.
So, we can calculate the age of the universe in seconds (Age_sec) by converting the megaparsecs to km:
Age (s) = $t \frac{s \cdot Mpc}{km} \times 3.09 \times 10^{19} \frac {km}{Mpc}$
age_sec=t*3.09e19
print(age_sec)
4.575325016985338e+17
That's a lot of seconds! We should convert seconds to years. Here's another fun fact: there are approximately $\pi$ x 10$^7$ seconds in a year.
More precisely, there are 60 (s/min) x 60 (min/hr) x 24 (hr/day) x 365.25 (days/yr)
sec_yr=60*60*24*365.25
print('%e'%(sec_yr))
3.155760e+07
Ok. so not exactly $\pi \times 10^7$, but close....
age_yr=age_sec/sec_yr
print(age_yr)
14498330091.59549
And now in billions of years:
age_byr=age_yr*1e-9
print(f'Age of the universe (in billions of years): {age_byr:.3f}')
Age of the universe (in billions of years): 14.498
Write a function that takes in a Hubble constant value and calculates the age of the Universe in billions of year
def age_of_universe(Hubble_constant):
age = 1.0/Hubble_constant
age_sec = age*3.09e19
sec_yr = 60*60*24*365.25
age_yrs = age_sec/sec_yr
age_byr = age_yrs*1e-9
return age_byr
print(f"Age of the universe (in billions of years): {age_of_universe(H0):.3f}")
Age of the universe (in billions of years): 14.498
Using other data sets to estimate the Hubble constant¶
Determining the Hubble constant continues to be a major avenue of astrophysical research. In fact, Wendy Freedman's group published another study (https://arxiv.org/abs/1907.05922) that is summarized in this short video:
https://www.youtube.com/watch?v=awcnVykOKZY
From that paper here is a visualization of Hubble constant determinations over the past 18 years:
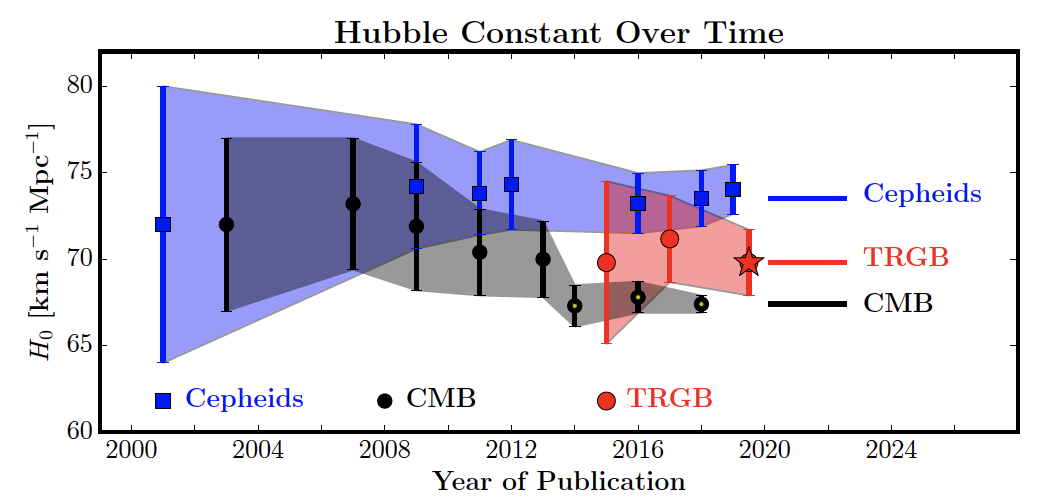
Let's look at another data set from the 2000 study to see how different data sets can lead to different answers.
Tully-Fisher Relation galaxy data¶
The total luminosity of a spiral galaxy (corrected to face-on inclination to account for extinction) is strongly correlated with the galaxy’s maximum (corrected to edge-on inclination) rotation velocity. This relation, calibrated via the Leavitt Law or TRGB, becomes a powerful means of determining extragalactic distances (Tully&Fisher 1977, Aaronson et al. 1986, Pierce&Tully 1988, Giovanelli et al. 1997). The TF relation at present is one of the most widely applied methods for distance measurements Freedman and Madore (2010)
Exercises:
- Import the 'Data/Freedman2000_IBandTullyFisher.csv' file.
data = pd.read_csv('data/Freedman2000_IBandTullyFisher.csv')
- Make a linear fit to determine the slope between
VCMBandD(Mpc).
model = LinearRegression()
model.fit(data[['D(Mpc)']],data['VCMB'])
LinearRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LinearRegression()
- Calculate the implied age of the universe from these TF galaxy data alone.
H0 = model.coef_[0]
print(f"Age of the universe (in billions of years): {age_of_universe(H0):.3f}")
Age of the universe (in billions of years): 12.679
Going even further out into the universe¶
Let's look at new data sets available for the classic Hubble problem. I found one published by Betoule et al. in 2014 http://dx.doi.org/10.1051/0004-6361/201423413.
In this paper, data are plotted using the parameters $z$ and $\mu$ which are related to the red shift velocity and distance. $z$ is the fractional shift in the spectral wavelength and $\mu$ is related to distance.
Here is a plot from the Betoule et al. paper:
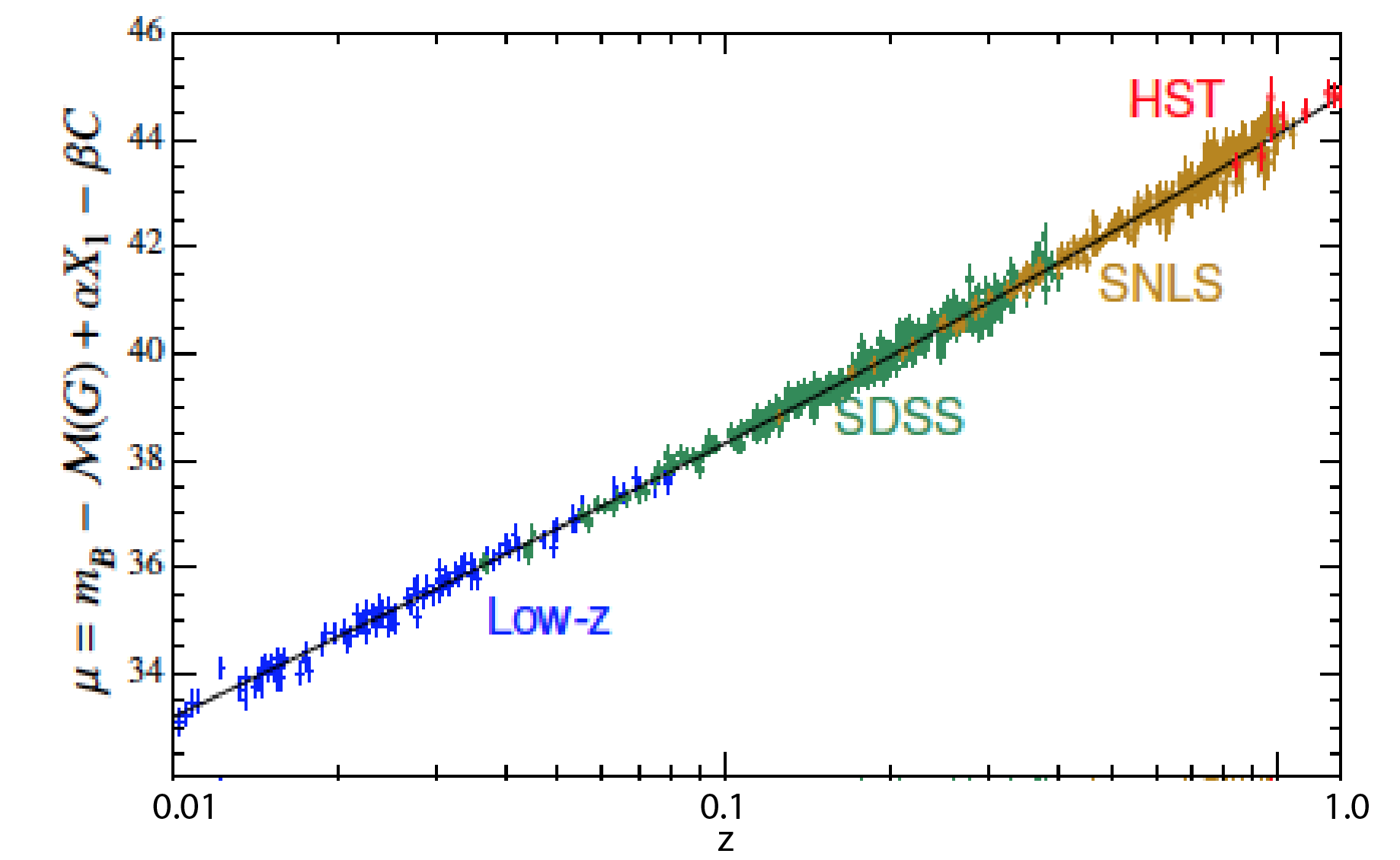
[Figure from Betoule et al., 2014.] These data are type Ia supernova from different observation collaborations
Notice that they plotted the data on a log scale. (This hides some surprising things.)
It turns out that we have been looking at data that are low-z (that is relatively close and low red shift). We need to convert $z$ and $\mu$ to distance and velocity to compare to the results we have considered thus far.
According to http://hyperphysics.phy-astr.gsu.edu/hbase/Astro/hubble.html
velocity $v$ (as fraction of the speed of light, $c$) is given by
${v\over c}= {{(z+1)^2-1} \over {(z+1)^2+1}}$
where $c=3 \times 10^8$ $m s^{-1}$.
And according to the Betoule et al. (2014) paper, $\mu$ relates to distance in parsecs $d$ like this:
$\mu = 5 \log \frac{d}{10}$
Let's read in the data (available from this website: http://cdsarc.u-strasbg.fr/viz-bin/qcat?J/A+A/568/A22#sRM2.2), which are averages of the data shown in the figure above,and take a peek.
Betoule_data = pd.read_csv('data/mu_z.csv',header=1)
Betoule_data.head()
| z | mu | |
|---|---|---|
| 0 | 0.010 | 32.953887 |
| 1 | 0.012 | 33.879004 |
| 2 | 0.014 | 33.842141 |
| 3 | 0.016 | 34.118567 |
| 4 | 0.019 | 34.593446 |
Now we can plot it the same way as the cosmologists did in the paper, using $\mu$ and $\log z$:
plt.figure
plt.scatter(Betoule_data['z'],Betoule_data['mu'],color='blue')
plt.xlabel('z')
plt.ylabel('$\mu$')
plt.semilogx()
plt.show()

To compare these new data with the previous considered data, we must do the following:
- Transform $z$ to velocity
- Transform $\mu$ to distance using the equations provided.
- Truncate the new dataset which goes to much farther distances than the 'old' data set
# speed of light in km/s
c = 2.9979e8 / 1000
# the formula for v from z (and c)
Betoule_data['velocity'] = c * (((Betoule_data['z']+1.)**2-1.)/((Betoule_data['z']+1.)**2+1.))
# convert mu to Gpc
Betoule_data['distance'] = 10000*(10.**((Betoule_data['mu'])/5.))*1e-9
plt.figure(figsize=(8,6))
plt.scatter(Betoule_data['distance'],Betoule_data['velocity'],
color='blue',label='1A Supernovae data (Betoule et al. 2014)')
plt.scatter(Supernova_data['D(Mpc)'],Supernova_data['VCMB'],
color='red',label='1A Supernovae data (Freedman et al. 2000)')
plt.ylabel('Velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.legend()
plt.show()

These data sets are similar to one another for the "close" objects, but we can see that a linear model doesn't work well for objects that are at greater distances.
To visualize this reality, let's plot the fit to the Freedman et al. 2000 data atop this plot.
model = LinearRegression()
model.fit(Supernova_data[['D(Mpc)']].values,Supernova_data['VCMB'].values)
y_pred = model.predict(Betoule_data[['distance']].values)
plt.figure(figsize=(8,6))
plt.scatter(Betoule_data['distance'],Betoule_data['velocity'],
color='blue',label='1A Supernovae data (Betoule et al. 2014)')
plt.scatter(Supernova_data['D(Mpc)'],Supernova_data['VCMB'],
color='red',label='1A Supernovae data (Freedman et al. 2000)')
plt.plot(Betoule_data['distance'],y_pred,
color='black',label='1A Supernovae fit to Freedman data')
plt.ylabel('Velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.legend()
plt.show()

Clearly this fit is quite poor.
Let's make a first-order polynomial fit to all the Betoule data and then plot the residual:
model = LinearRegression()
model.fit(Betoule_data[['distance']].values,Betoule_data['velocity'].values)
y_pred = model.predict(Betoule_data[['distance']].values)
plt.figure(figsize=(8, 10))
plt.subplot(2,1,1)
plt.scatter(Betoule_data['distance'],Betoule_data['velocity'])
plt.plot(Betoule_data['distance'],y_pred,color='orange',)
plt.title('data and a polynomial degree 1 fit')
plt.ylabel('Velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.subplot(2,1,2)
plt.scatter(Betoule_data['distance'],Betoule_data['velocity']-y_pred)
plt.title('residuals of a polynomial degree 1 fit')
plt.ylabel('Residual velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.tight_layout()
plt.show()

There is a lot of structure to the residual of this degree 1 fit. Let's try a degree 2 polynomial fit (known as quadratic):
$f(x)=ax^2+bx+c$
model = LinearRegression()
poly = PolynomialFeatures(degree=2)
X = poly.fit_transform(Betoule_data[['distance']].values)
model.fit(X, Betoule_data['velocity'].values)
y_pred = model.predict(X)
plt.figure(figsize=(8, 10))
plt.subplot(2,1,1)
plt.scatter(Betoule_data['distance'],Betoule_data['velocity'])
plt.plot(Betoule_data['distance'],y_pred,color='orange',)
plt.title('data and a polynomial degree 2 fit')
plt.ylabel('Velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.subplot(2,1,2)
plt.scatter(Betoule_data['distance'],Betoule_data['velocity']-y_pred)
plt.title('residuals of a polynomial degree 2 fit')
plt.ylabel('Residual velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.tight_layout()
plt.show()

There is a lot of structure to the residuals of this degree 2 fit (and the residuals are still high). Let's try a degree 3 polynomial fit (known as cubic):
$f(x)=ax^3+bx^2+cx+d$
model = LinearRegression()
poly = PolynomialFeatures(degree=3)
X = poly.fit_transform(Betoule_data[['distance']].values)
model.fit(X,Betoule_data['velocity'].values)
y_pred = model.predict(X)
plt.figure(figsize=(8, 10))
plt.subplot(2,1,1)
plt.scatter(Betoule_data['distance'],Betoule_data['velocity'])
plt.plot(Betoule_data['distance'],y_pred,color='orange',)
plt.title('data and a polynomial degree 3 fit')
plt.ylabel('Velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.subplot(2,1,2)
plt.scatter(Betoule_data['distance'],Betoule_data['velocity']-y_pred)
plt.title('residuals of a polynomial degree 3 fit')
plt.ylabel('Residual velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.tight_layout()
plt.show()

Can a degree 4 polynomial fit do better?
$f(x)=ax^4+bx^3+cx^2+dx+e$
model = LinearRegression()
poly = PolynomialFeatures(degree=4)
X = poly.fit_transform(Betoule_data[['distance']].values)
model.fit(X,Betoule_data['velocity'].values)
y_pred = model.predict(X)
plt.figure(figsize=(8, 10))
plt.subplot(2,1,1)
plt.scatter(Betoule_data['distance'],Betoule_data['velocity'])
plt.plot(Betoule_data['distance'],y_pred,color='orange',)
plt.title('data and a polynomial degree 4 fit')
plt.ylabel('Velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.subplot(2,1,2)
plt.scatter(Betoule_data['distance'],Betoule_data['velocity']-y_pred)
plt.title('residuals of a polynomial degree 4 fit')
plt.ylabel('Residual velocity (km s$^{-1}$)')
plt.xlabel('Distance (Mpc)')
plt.tight_layout()
plt.show()

That looks about the same as the cubic so might as well stick with that one as a working model.
That the velocity-distance relationship is not linear is taken as evidence that the expansion of the universe is accelerating. This acceleration is attributed to dark energy:
In a matter-dominated universe, the expansion velocity of the Universe slows down over time owing to the attractive force of gravity. However, a decade ago two independent groups (Perlmutter et al. 1999, Riess et al. 1998) found that supernovae at z ∼ 0.5 appear to be about 10% fainter than those observed locally, consistent instead with models in which the expansion velocity is increasing; that is, a universe that is accelerating in its expansion. Combined with independent estimates of the matter density, these results are consistent with a universe in which one-third of the overall density is in the form of matter (ordinary plus dark), and two-thirds is in a form having a large, negative pressure, termed dark energy. Freedman and Madore (2010)